核心判断
它厉害的地方,不是”更复杂”,而是”更准地抓住误差来源”。
Mask R-CNN 沿用 Faster R-CNN 的成熟骨架,只做两处关键升级:RoIAlign 解决像素级错位,FCN mask head 负责实例轮廓。结构改动很小,收益却非常大。
核心判断
Mask R-CNN 沿用 Faster R-CNN 的成熟骨架,只做两处关键升级:RoIAlign 解决像素级错位,FCN mask head 负责实例轮廓。结构改动很小,收益却非常大。
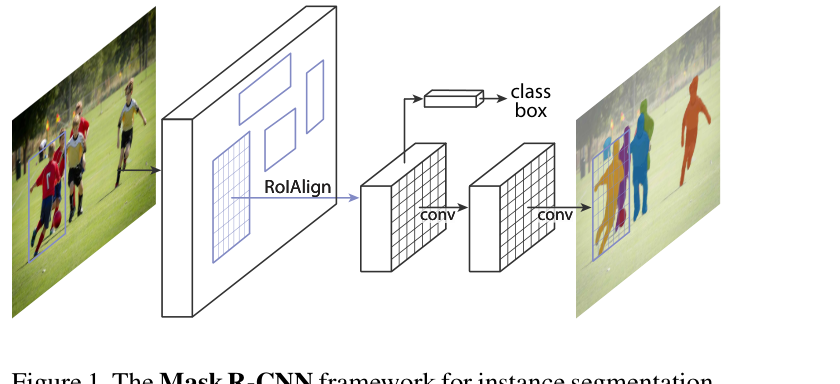

这篇论文想做的,不是推翻检测框架,而是在保留 Faster R-CNN 优势的同时,把实例分割这块准确补上。
RPN 在全图上生成候选框,相当于先做一轮成本更低的区域筛选。
对每个 RoI,系统同时判断类别、微调框位置,再额外预测一个实例 mask。
两阶段检测母体:RPN + RoI 头。
多尺度特征金字塔,让大小目标都能接到合适层级。
| 方法 | 主干 | mask AP |
|---|---|---|
| MNC | ResNet-101 | 24.6 |
| FCIS | ResNet-101 | 29.2 |
| FCIS+++ | ResNet-101 | 33.6 |
| Mask R-CNN | ResNet-101-FPN | 35.7 |
| Mask R-CNN | ResNeXt-101-FPN | 37.1 |



把每个关键点看成一个非常稀疏的二值 mask,于是关键点检测也能接到同一套 RoI 特征上。
| COCO keypoint AP | 63.1 |
|---|---|
| 2016 冠军系统 | 61.8 |
| 论文报告速度 | 5 fps |
一旦实例级 RoI 表征足够稳定,box、mask、keypoint 这些输出头都能自然插上去。